
Ok, so let's say you've decided to implement Sovereign Stack. The first place to focus your attention is on your network setup. You can always buy new equipment for a new deployment, or you can simply apply the concepts of this website to your existing network infrastructure.
Typically each Data Center has a unique public IP address that terminates on the WAN side of the firewall. The Firewall, Switch, and DMZs collectively are referred to as the "network underlay" as these devices provide the most basic networking functions. Functions on the network underlay include DHCP (for creating reservations) and DNS names for your various deployments VMs and cluster hosts.
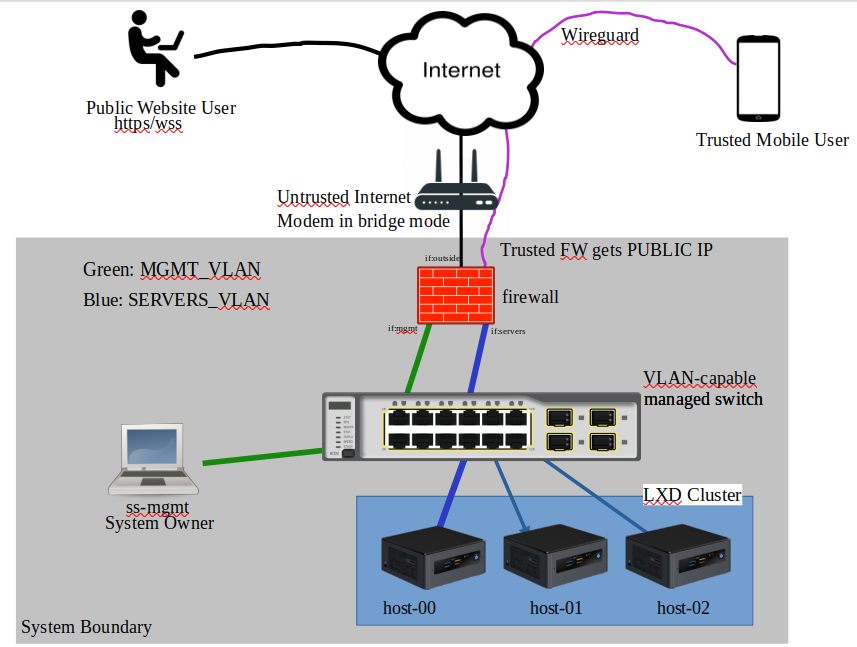
Each data center also contains AT LEAST ONE VLAN-capable managed switch. Redundant switch and firewall configurations are future work.
Availability
Although each Sovereign Stack deployment attempts to maintain high levels of up time at each deployment, some operations such as TLS enrollment/renewal REQUIRE that all services be taken down temporarily. Taking services down for troubleshooting may also be required at any given data center.
Geographic Redundancy
If you're operating a business where service interruptions have a large impact on revenue streams, it may make sense to deploy two or more Sovereign Stack data centers separated by a reasonable physical distance, perhaps in different legal jurisdictions and ISPs. Geo-redundant configurations help companies meet their business continuity objectives.
The management machine deploys software to one or more cluster hosts across your various data centers. You decide what is deployed at each site, but the general approach is to deploy read-only caching proxies which mirror a primary writable location.
Disaster Recovery
Disaster Recovery is achieved by reestablishing data center hardware, then performing a restoration. Sovereign Stacks keeps encrypted duplicity archives on the management machine which form the basis for recovery of user data.
Each time you execute Sovereign Stack, a backup archive is created and stored on your management machine.
If a data center suffers a disaster, that data center should be removed from DNS so clients aren't directed to the affected data center. (Automating this is future work)
You can then work on restoring service by repairing the offline data center and restoring from backup.
Local High Availability (Local-HA)
Sovereign Stack currently does not support Local-HA. This is future work. The idea with Local-HA is you have a set of three or more cluster hosts all sitting behind a load-balancing Virtual IP. I might consider adding a redundant upstream ISP connection and firewall+switch combination w/failover as well. This is future work.
By default, Sovereign Stack requires deployments be taken down before a backup is taken. It is future work to enable a continuous online backup solution.
Scalability
Native ways to scale the system include 1) adding additional cluster hosts at each data center and situating them behind a round-robin VIP at the firewall, and 2) by running multiple geographically separate data-centers using Geographically-sensitive DNS resolution. Item (2) is essential for achieving 100% service up-time.
You should avoid using any trusted third party to scale your system (e.g., caching CDN). Introducing a Trusted Third Party represents a vulnerability in your system design.